💾 Archived View for dioskouroi.xyz › thread › 29421898 captured on 2021-12-04 at 18:04:22. Gemini links have been rewritten to link to archived content
⬅️ Previous capture (2021-12-03)
-=-=-=-=-=-=-
________________________________________________________________________________
Source of this post likely from [1]
[1]
https://news.ycombinator.com/item?id=29417296
Yep, I posted this today after the author of gigablast posted a comment in this
https://news.ycombinator.com/item?id=29417061
today
Matt Wells who wrote the majority of the code for gigablast is someone I have been following online for a long time. I used to live for
http://gigablast.com/rants.html
updates. Gigablast being an amazing example of what one person can do given the time and effort. If you look around for articles and interviews by him you get some nice insights that would never come from the likes of Google, although Bing has some very good in depth technical discussions such as how bitfunnel works. It’s also nice to look through the code of it and see how things like porn filters were implemented.
It’s also nice to know that for a while in internet history gigablast was mentioned in the same breath as google. An amazing achievement at the time for a single person against the core google product.
I wish that someone with some design chops could work on it for a few weeks though. Or it was rolled back to the design from around 2006 with the rocket logo. I really liked that design.
I really wish I had the courage to strike out on my own like Matt has. I have written a few search engines, but a general purpose one from scratch on my own hardware is unlikely to ever happen, as much as I would love to do it.
That’s for inspiring me so much Matt if you do read this (notice me senpai!). Oh and sorry for abusing your XML api so much. I was poor at the time and needed some search results.
A few choice articles,
https://queue.acm.org/detail.cfm?id=988401
https://www.abc.net.au/news/science/2021-02-14/google-news-m...
thanks ben, you are too kind.
I second this - thanks for building this. It's an unbelievably inspiring achievement. It's my default search engine, and I'm really glad it exists.
Wow even knows me by my first name too. Very humbled. Once again thanks for being so open with what you have done.
hey thanks for the recognition, people. :) finally, all my problems are solved. this comment is here for hacker news karma points.
Hey Matt, would you consider making a search box (input with id="q") a bit wider? I can type only around 15 characters before the beginning of search query becomes "cut off".
Seconded.
I went to check out a few example searches and the too-narrow search bar is the first annoyance I found.
The next annoyance was that the crawled index seems much smaller than google's or bing's. I looked for things I know exist on twitter, on an old wordpress blog, on obscure websites I frequent: forcing terms to not be skipped using + I could see that none of my test cases were in the index.
The too small text box is also a pain when deleting the query in order to type a new one on mobile. A clear button would mitigate some of this pain although making the field larger would probably be sufficient
I noticed there were IPs in the source code that seemed to reference yours, and mabye others', home IP addresses. I'm curious if you run any parts of either the crawling, indexing, or searching from home networks?
I'm asking since I'm working on similar/different crawling problems that would make some stuff easier to just handle from the hardware I have at home, and have always assumed the provider would shut it down. Have you had any issues with that?
*throws karma at the screen*
“Gigablast has teamed up with Imperial Family Companies to create a next generation private search engine, private.sh.”
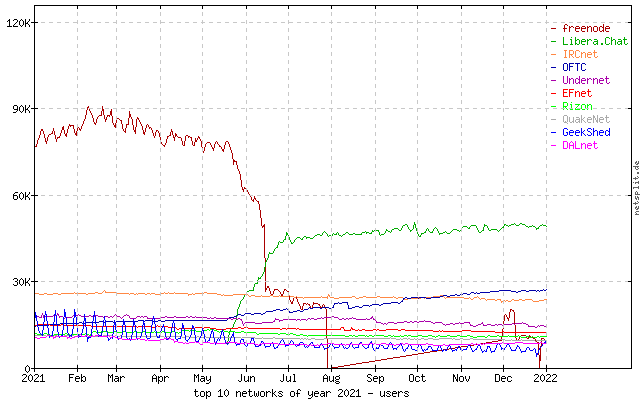
Imperial Family Companies are the people who essentially destroyed [1] the freenode IRC network, aren’t they?
[1]
https://netsplit.de/networks/history/top10_2021u.png
Yes, the same ones [1]. They are an investment firm that was formerly known as London Trust Media. You can see they have listed both "IRC" (links to irc.com) and "freenode" in their portfolio. [2]
[1]
https://lists.ubuntu.com/archives/ubuntu-irc/2021-May/001923...
[2]
(hover over "Technology)
let's just make sure we destroy everything they invest in
It's hard to believe they'd take money from someone that attacked so many open source projects earlier this year by leveraging "donations". They should be careful.
At the same time, they're in a position to consent to a transition, not sure there's a community of collective ownership here like with freenode
I used to donate my idle cpu to seti@home back in the day. Wonder if the same can be done for creating an open search engine to compete with Google.
Also since the resources are crowd sourced it can make it easy to get around rate limits and anti scraping too.
Perhaps not weirdly I had the same thought yesterday [1].
was suggested in response.
[1]
https://news.ycombinator.com/item?id=29417925
You can do this with Yacy right now,
but it's not great for results generally.
I have often wondered if something built on activity pub or like that would be an option allowing people to group servers with peers they like or trust. Its something I want to implement actually and may get around to doing one of these days.
Well for starters, one could implement the API to return ActivityStreams formatted responses. That would be a good start to being compatible with the fediverse and stuff while not going insane in implementing a full and proper ActivityPub service.
Been there, done that, way better tool for "lower level" features.
[0]
https://www.w3.org/TR/activitystreams-core/
That roughly what I thought. I’m not familiar with activitypub at all. I will probably investigate this deeper.
You see to have some knowledge in this area. Do you have any suggestions of places to look to achieve something like this?
I don't think it would be that easy. You need to distribute the indexing data. But you could federate search servers and have them send queries to others.
I know the usual thing against crypto, but I wonder whether a gridcoin model would work.
That's a really cool idea!
Hi @gbmatt, amazing work!
What is the business history of it? Did companies /investors show interest in acquiring it? What do you think needs to be done in terms of business development to extend the index to cover the modern internet, as well as get whitelisted (and shortlisted) properly by cdns?
Competition in search would be great.
If this is a one-person project, then that is really cool, but if it wants to be a serious contender in consumer-facing search, then it is probably time to hire an employee with complementary skills.
It's been around since early google days, and that seems to be when most of the HTML was written. Every single page has several HTML errors... so definitely needs help there. Basic things like HTML tables are not closed / switching <td> and <tr> around etc.
Matt is a great guy and it does not have the credit he should have!
Same thing for Gigablast!
It is amazing what one person alone can accomplish.
Congratulations for that, Matt!
You've done impossible things with few resources!
It's a shame to have so many money given to so many projects and no one ever remembers Gigablast.
(About private.sh: I think it would be nice to have image search on private.sh)
> It is amazing what one person alone can accomplish
I was also wondering how Matt did all this mostly alone until I discovered he joined HN only nine months ago. ;)
Well, pirate bay is returned in search results, so that's a good start...
I tried to submit my website to Gigablast, but apparently it costs 25 cents.
This doesn't make any sense to me for a search engine.
it found this:
https://gigablast.com/search?c=main&qlangcountry=en-us&q=how...
Which is definitely a good sign of a competent search engine.
Initial searches are very promising. Is there a good way to add this as my default search engine in Firefox?
If you don't want an extension, another option is to find it on Mycroft Project [0], choose Gigablast, and on the "Install plugin" page, right click the address bar and choose "Add Gigablast". Then you can set it as your default from the Firefox search settings.
[0]:
https://mycroftproject.com/search-engines.html?name=gigablas...
You could give
https://addons.mozilla.org/en-CA/firefox/addon/gigablast-sea...
a try.
I saw this in a thread earlier today. I couldn't understand why it has a login and account. They seem to be the anti-Google and and anti-personalization search engine.
You don't need an account to make searches though :
https://gigablast.com/index.html
If you have an account you can probably log your queries.
It looks, you need a account to add url-s.
"You need to login to use the add url tool. "
"Each added url is $0.25."
good question
I cant go back to search results from private.sh.
"Clients" --> Error = Not Found
:')
I like the idea of a web search engine that works for searching the web.
Honestly, I find this search engine pretty dang usable. I've thrown technical to frivolous at it, and i like the mix of results.
Furthermore, the client-side javascript on private.sh encrypts any query done on private.sh so that only Gigablast can read it. Therefore, no single party has access to both the IP address and the query. This is something that is truly unique and truly powerful, and, right now, only private.sh can supply this level of privacy.
Run proprietary Javascript for privacy - what a fallacious concept. Going to assume this service is a honeypot or run by incompetent staff - pass.
the javascript is run by your browser, so you can fully audit it.
It's still served by the site and I doubt most are interested or capable in auditing software to perform routine online tasks.
I am not sure there are good solutions besides going off browser.
P.S. I was involved in user authorization, attestation and privacy flows for a particular product recently and the browser was always where shit hit the fan. The web features are just not made with simplicity and privacy in mind. Then again we had more complex constraints.
There's an extension as well [1]. This means that the code is not being served by the server in this use case.
[1]
https://private.sh/extension.html
Only Gigablast can read it means it is not private
{kind=link}